Testing Benford's Law on COVID-19 italian Datasets
Since COVID-19 is the year most hot topic i decided that might be a good idea to test my newly created experiment with Go in order to check the Benford Law on public datasets.
So first of all what is the Benford's Law?
According to online resources the Benford’s law (also called the first digit law) states that the leading digits in a collection of data sets are probably going to be small. In a nutshell, if we have a dataset containing numbers we will most likely find numbers starting with 1,2,3,4,5 since these will cover almost 75% of the number distribution (e.g. starting with 1 - 31% , 2 17% etc..)
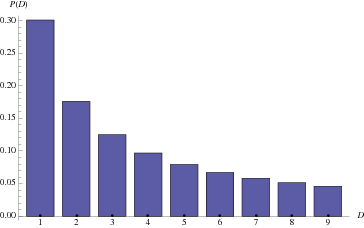
The experiment
My little experiment starts with the COVID-19 Dataset in order to see if those data are considered Benford's Law "Compliant".
The
dataset is populated by COVID-19 cases on a daily basis around 17-18 PM
CET from the italian govt's "Protezione Civile", if you are interested
into this data you can find it here:
- https://github.com/pcm-dpc/COVID-19
For
almost one year i integrated these datasets into a Telegram Channel in
order to track down cases and make some stats that you don't get from
the TV stations (if you are interested here is the link: https://t.me/covidinfoshare - powered by a scheduled Gitlab CI pipeline 🙂)
Returning
back to our Benford's Law, here are the results of my small script runs
against the same dataset but on different scopes such as
regions,province and entire nation:
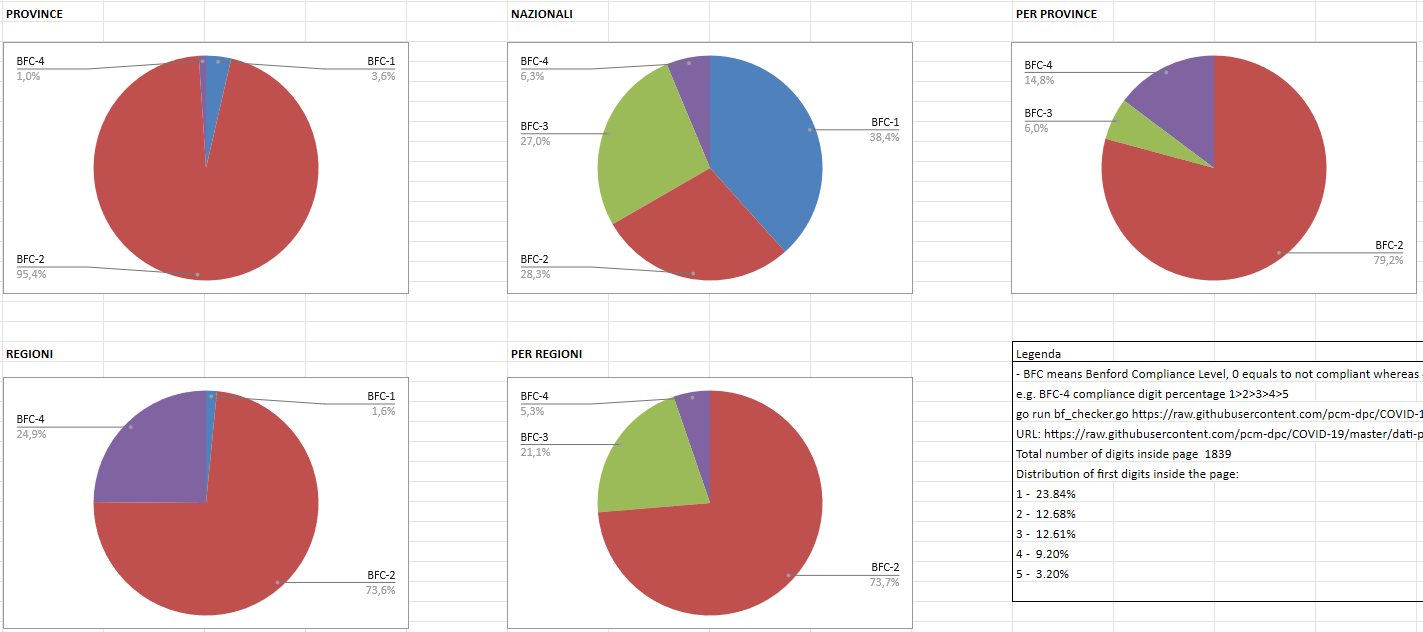
TLDR: BFC-0 Not Benford Law Complaint, BFC-4 Compliant till the fifth digit
Google Sheet link here
In case you want to run the bf_checker on your machine feel free to clone the repo here and execute the command to process the remote dataset (you can find the samples in the same repo).
As
you can see the results are not 100% Benford's Law Compliant as you may
expect but we can see a clear pattern from local level
(dataset-province) to nation level (dataset-nazionali) because of the
granularity of data (if you have more numbers most likely you will reduce
noise such as timestamps/dates an so on)
Another interesting
thing about this first digit law is the enormous number of
papers/studies around this law that shows clearly that can be used for
different scopes such as:
- Forensics (e.g. fake pictures, file manipulation)
- Fraud checks (Taxes payment forms...)
- Data validation
But
there are always limits because not any kind of dataset can be checked
for example running the checker on log files may lead to a very large
number of 2 digits (2021/xx/xx + time etc..) thus making the results
less relevant (or forcing the number 2 on the first digit stats)
Links and Resources:
- Benford's checker Github
- Dataset Protezione Civile - Italian COVID-19 data
- https://mathworld.wolfram.com/BenfordsLaw.html
- Documentary: Connected 2020 - Episode - Numbers
wq!
CTRL+R(reverse-i-search)`add':
git add . && git commit -m "2021-03-19-benford-law-checker
Commit" && git push origin master
Comments
Post a Comment